Parquet, ORC, Avro and CSV Benchmarking
There is a variety of file format choices in the Hadoop ecosystem. The popular file formats are ORC, Parquet, CSV and Avro. Parquet and ORC are both columnar-storage type whereas ORC uses the row-based format.
This article describes the steps to test the performance of these file formats in both Hive LLAP and Impala query engine using Cloudera Data Warehouse (CDW) with one executor engine pod in the CDP Private Cloud platform.
Prerequisites
- The performance benchmarking tests are carried out using CDW on the CDP Private Cloud (Openshift) platform with the following hardware specification.
| CPU | Intel(R) Xeon(R) Gold 5220R CPU @ 2.20GHz |
| Memory | DIMM DDR4 Synchronous Registered (Buffered) 2933 MHz (0.3 ns) |
| Disk | SSD P4610 1.6TB SFF |
A random sample data of 300 million CSV rows is produced using a python script with the faker generator. The schema of each row is sequenced as
Lastname, Firstname, MSISDN, Date of Birth, Postcode, Cityas illustrated below.Maria,Harmon,32378521,1998-11-14,17,30766,Durhammouth Anne,Adams,29481072,1982-10-28,36,70830,Deannabury Deborah,Sanders,21125797,2002-04-07,56,63993,New RonaldlandCopy the file to the HDFS cluster.
# hdfs dfs -put 300mil.csv /tmp/sampledata/ # hdfs dfs -du -h /tmp/sampledata/ 16.0 G 47.9 G /tmp/sampledata/300mil.csvIn CDW, create a
hiveand animpalavirtual warehouse with only 1 executor each.
Testing Procedure
Access
Huetool of thehivevirtual warehouse. Create databasedb1.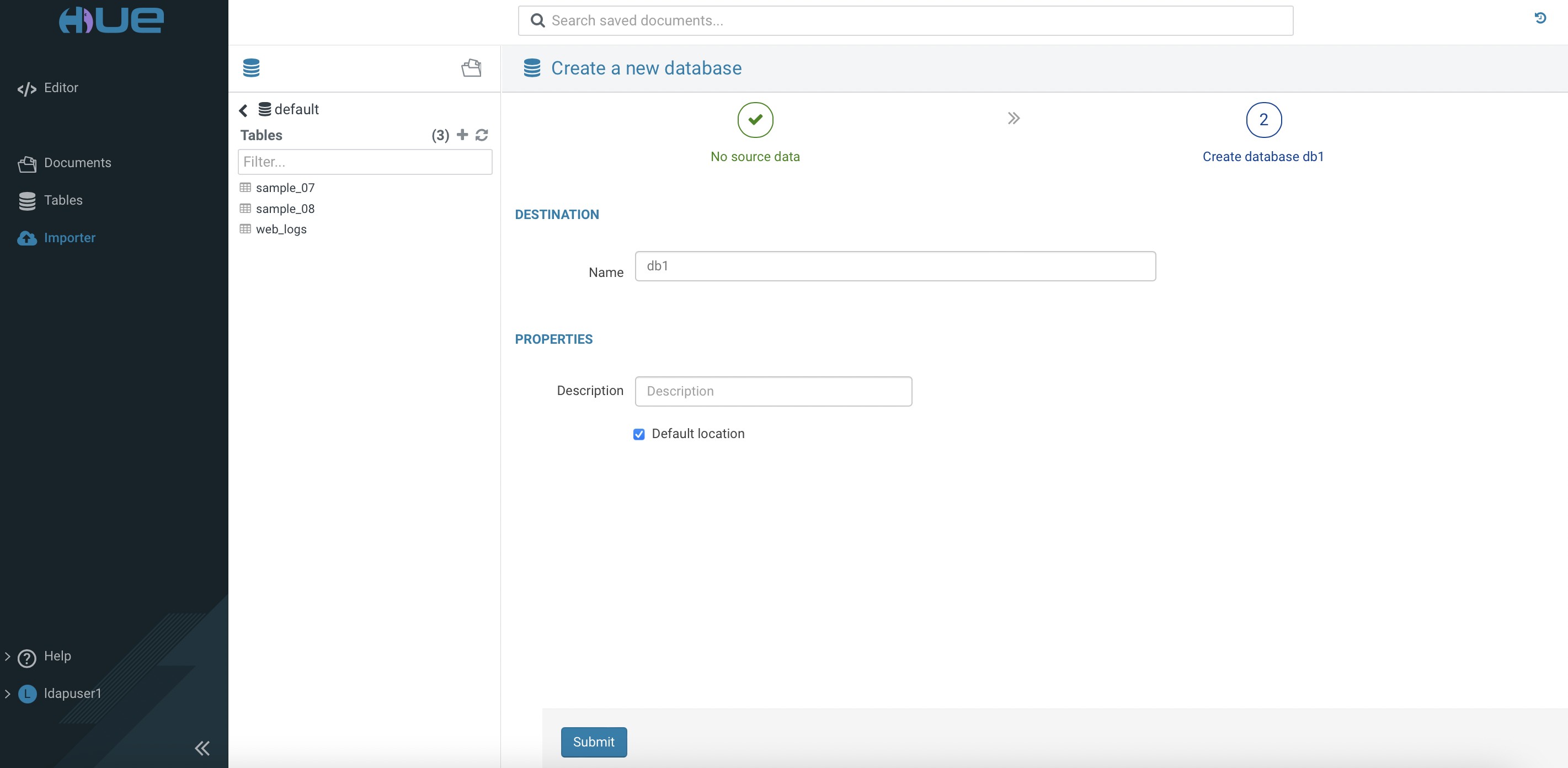
Use the SQL Editor to create an external table in the database
db1.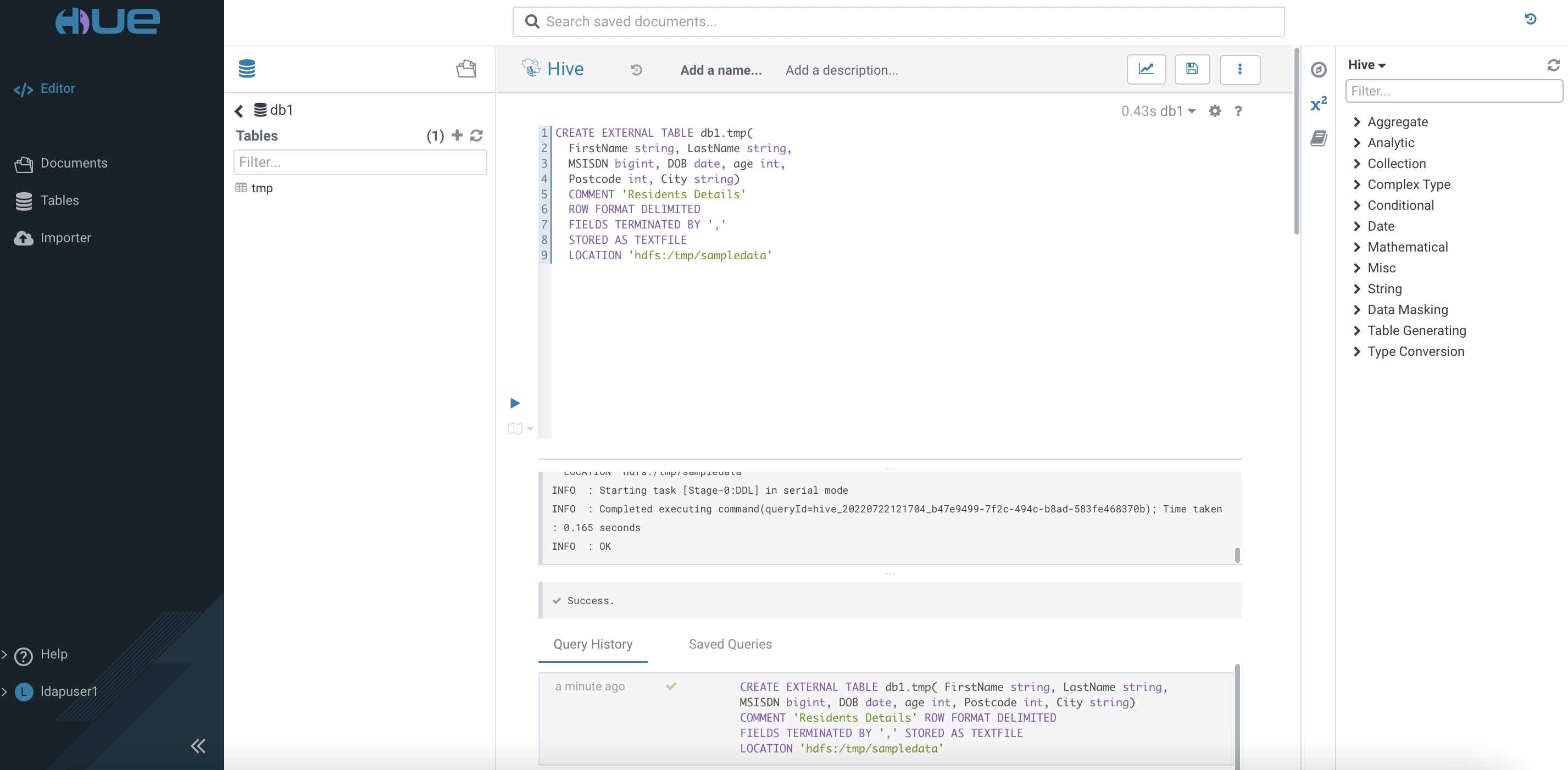
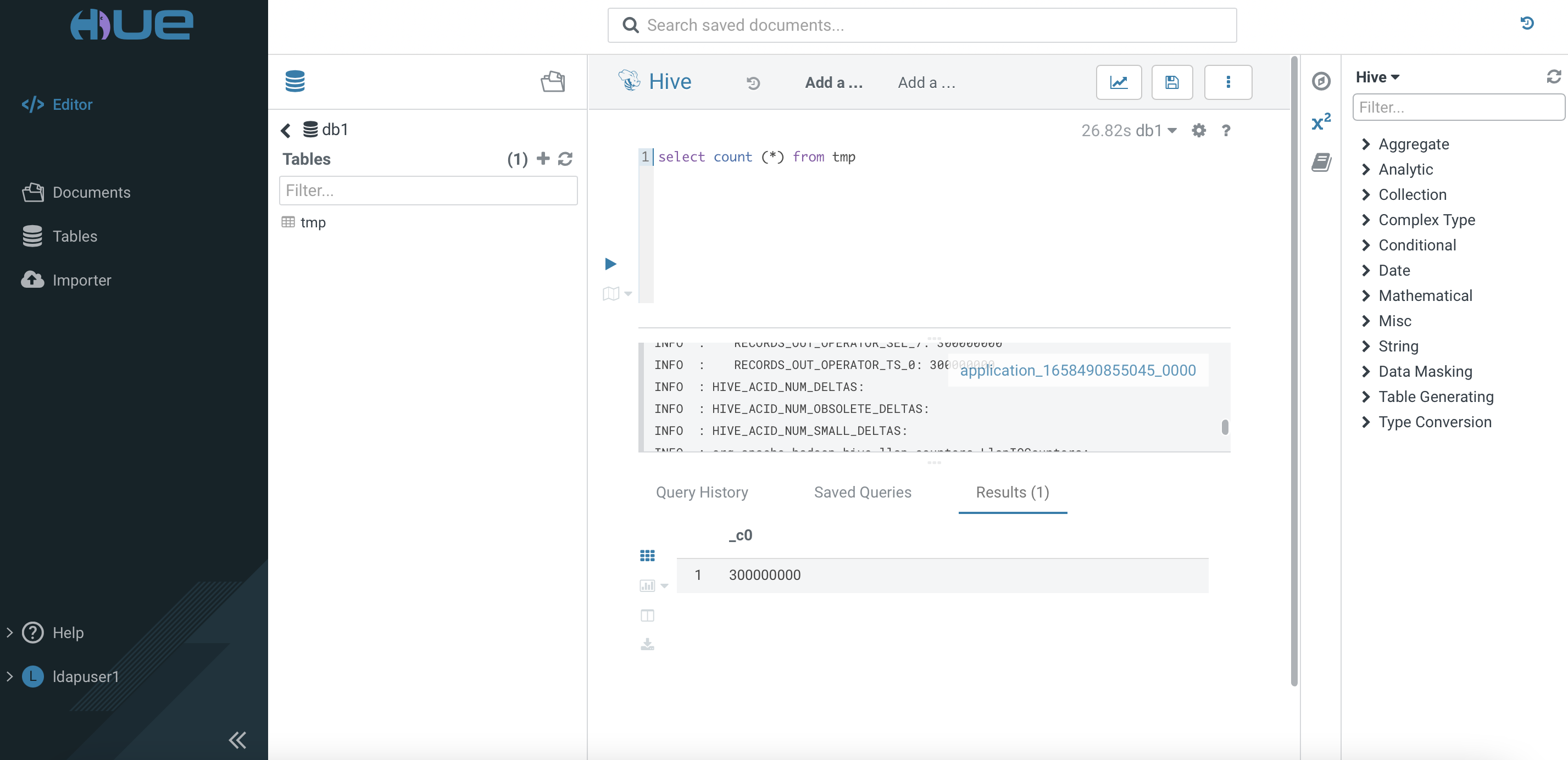
Execute the following command and take note of the speed result. Repeat running the same command and jot down the result again.
Create a Hive managed table using the ORC file format based on the schema as shown below. The data type of the specific file format can obtained here.
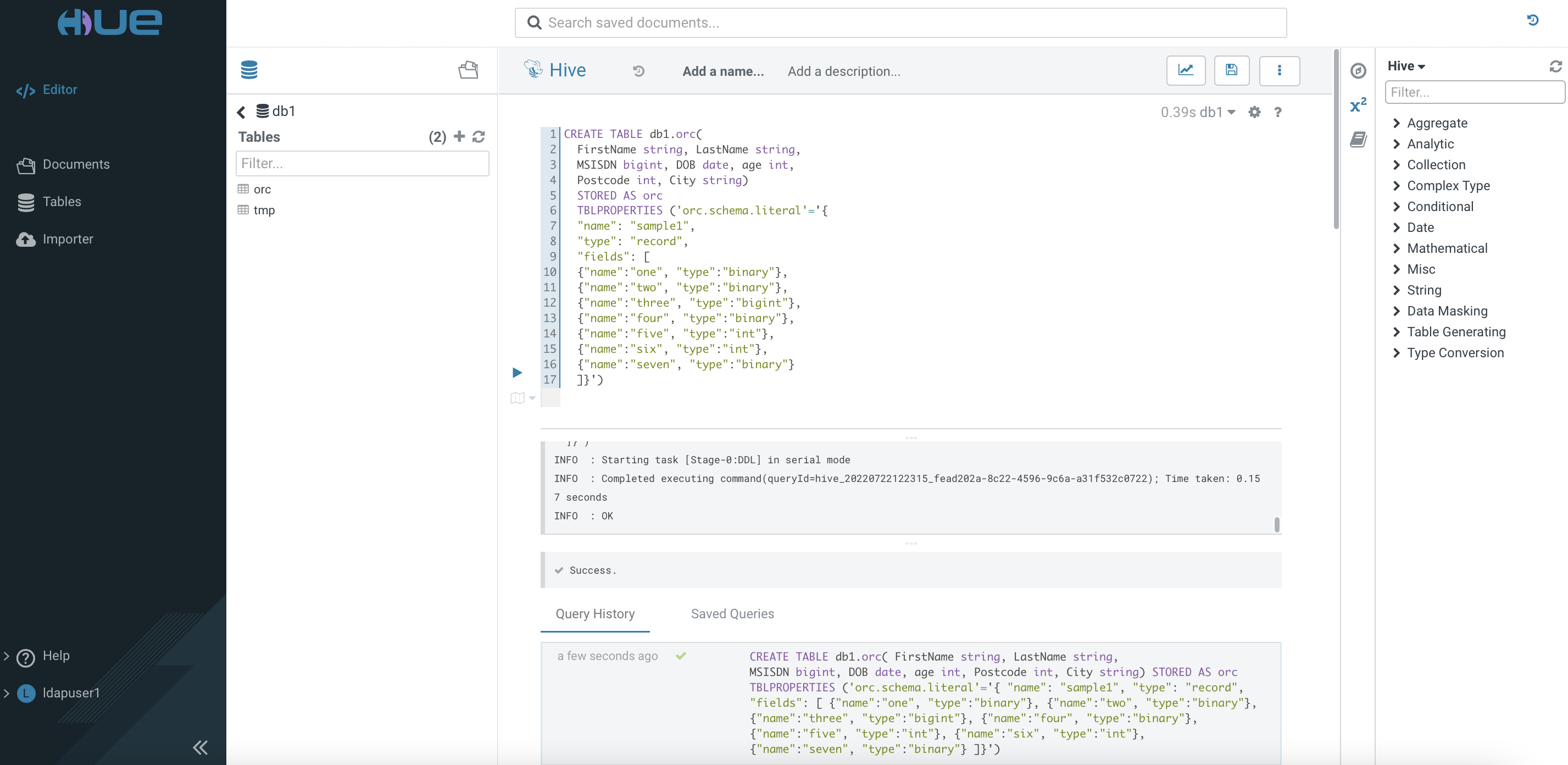
Insert the data from the external
tmptable into this newly created ORC-based table. Take note of the speed to execute this task completely.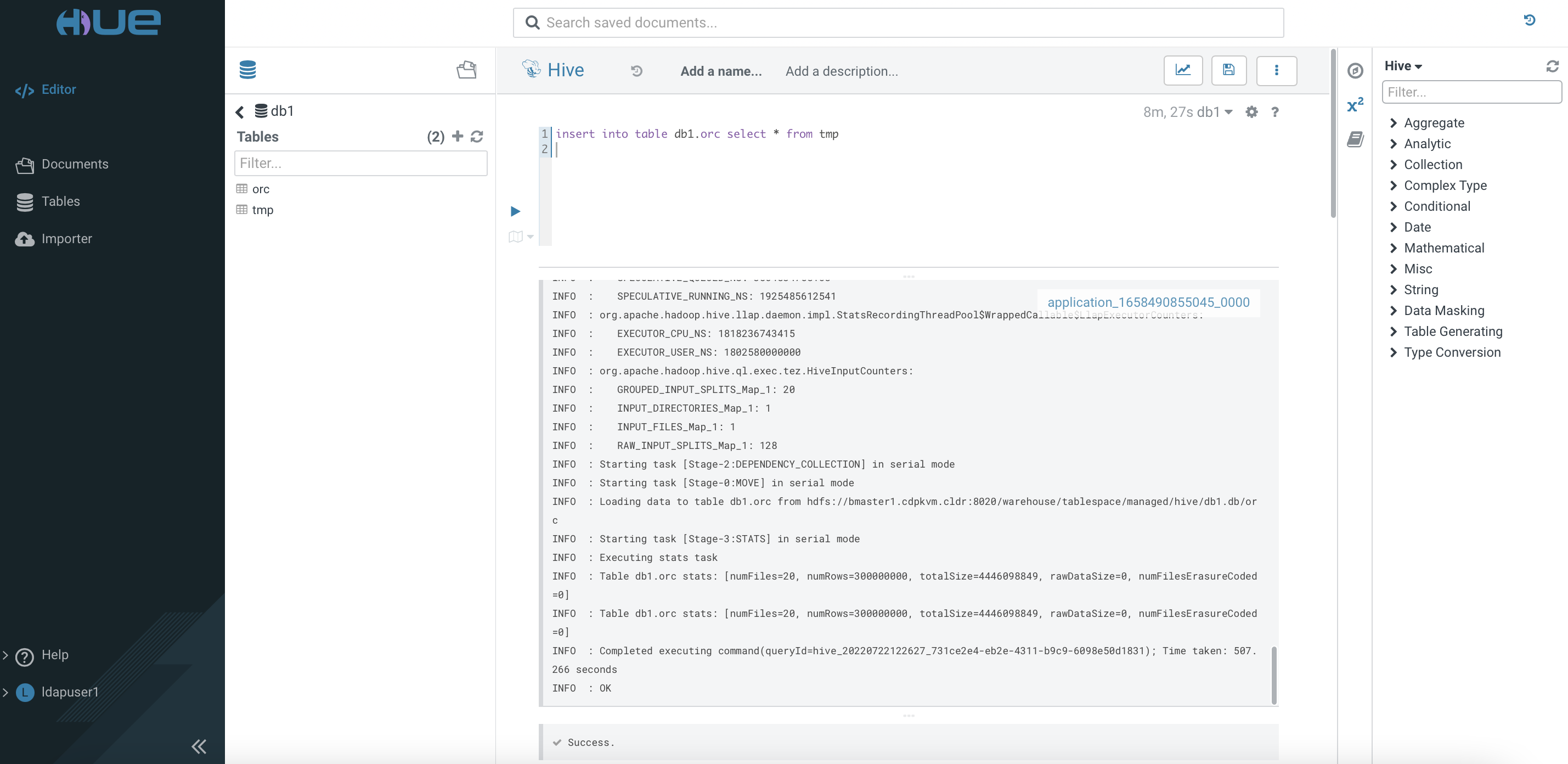
Check the result of the loaded data.
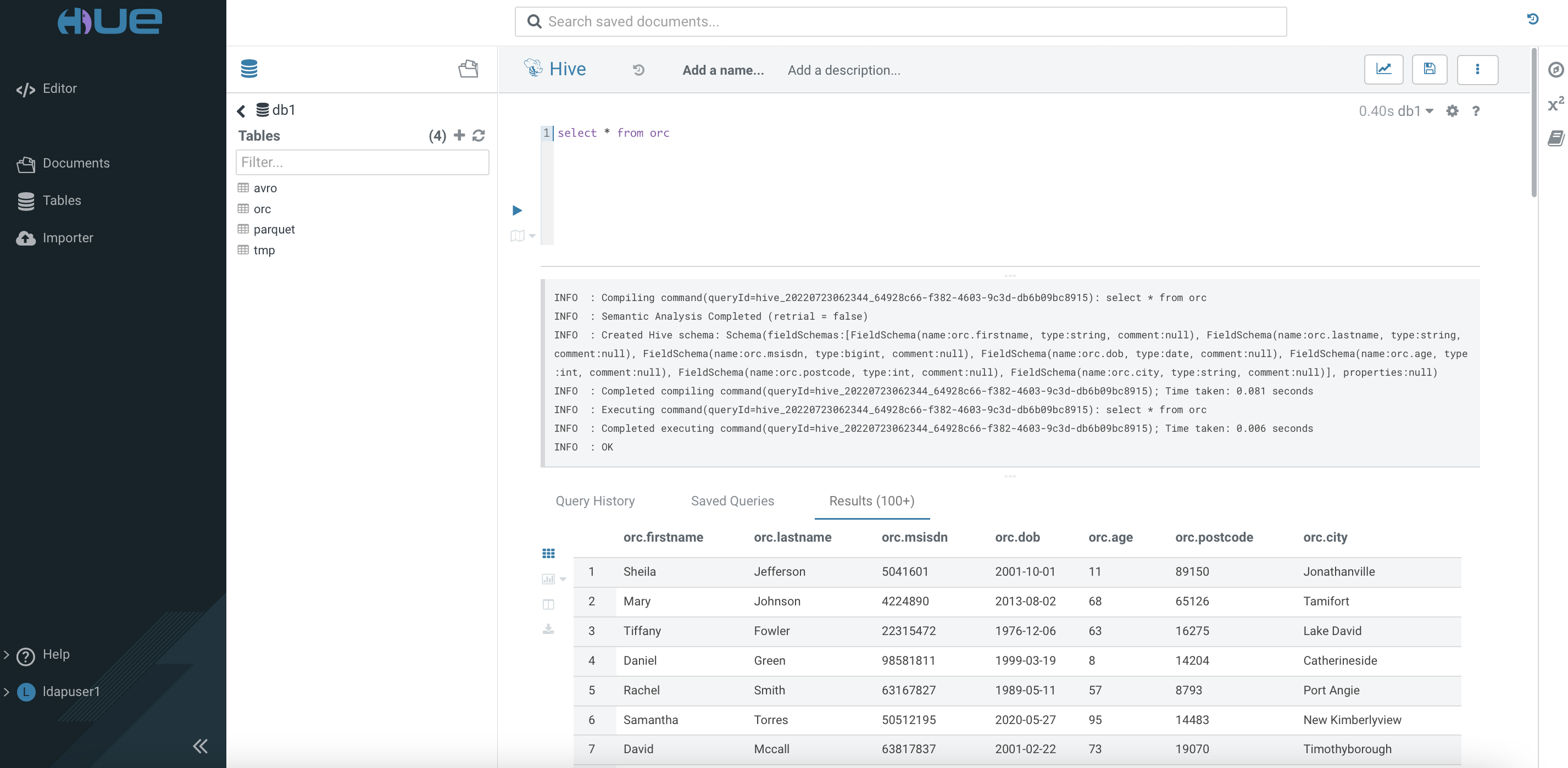
Run the following SQL queries twice and take note of the speed result.
SELECT COUNT (*) FROM db1.orc;SELECT AVG(age) FROM db1.orc where lastname = 'Davis' and age > 30 and age < 40;Repeat step 4 for file format Parquet by creating a table with the following schema.
CREATE TABLE db1.parquet( FirstName string, LastName string, MSISDN bigint, DOB date, age int, Postcode int, City string) STORED AS parquet TBLPROPERTIES ('parquet.schema.literal'='{ "name": "sample1", "type": "record", "fields": [ {"name":"one", "type":"binary"}, {"name":"two", "type":"binary"}, {"name":"three", "type":"INT64"}, {"name":"four", "type":"date"}, {"name":"five", "type":"INT32"}, {"name":"six", "type":"INT32"}, {"name":"seven", "type":"binary"} ]}')Run the following SQL queries twice and take note of the speed to run them completely.
SELECT COUNT (*) FROM db1.parquet;SELECT AVG(age) FROM db1.parquet where lastname = 'Davis' and age > 30 and age < 40;Repeat step 4 for file format Avro by creating a table with the following schema.
CREATE TABLE db1.avro( FirstName string, LastName string, MSISDN bigint, DOB date, age int, Postcode int, City string) STORED AS avro TBLPROPERTIES ('avro.schema.literal'='{ "name": "sample1", "type": "record", "fields": [ {"name":"FirstName", "type":"string"}, {"name":"LastName", "type":"string"}, {"name":"MSISDN", "type":"long"}, {"name":"DOB", "type":"string"}, {"name":"age", "type":"int"}, {"name":"Postcode", "type":"int"}, {"name":"City", "type":"string"} ]}')Run the following SQL queries twice and take note of the speed to run them completely.
SELECT COUNT (*) FROM db1.avro;SELECT AVG(age) FROM db1.avro where lastname = 'Davis' and age > 30 and age < 40;Access
Huetool of theImpalavirtual warehouse. Create databasedb2.Use the SQL Editor to create an external table in the database
db2.Create a managed table using the Parquet file format based on the schema as shown below.
CREATE TABLE db2.parquet2( FirstName string, LastName string, MSISDN bigint, DOB date, age int, Postcode int, City string) STORED AS parquet TBLPROPERTIES ('parquet.schema.literal'='{ "name": "sample1", "type": "record", "fields": [ {"name":"one", "type":"binary"}, {"name":"two", "type":"binary"}, {"name":"three", "type":"INT64"}, {"name":"four", "type":"date"}, {"name":"five", "type":"INT32"}, {"name":"six", "type":"INT32"}, {"name":"seven", "type":"binary"} ]}')Insert the data from the external
tmptable into this newly created Parquet-based table. Take note of the speed to execute this task completely.INSERT INTO table db2.parquet2 SELECT * from db1.tmp;Run the following SQL queries twice and take note of the speed result.
SELECT COUNT (*) FROM db2.parquet2;SELECT AVG(age) FROM db2.parquet2 where lastname = 'Davis' and age > 30 and age < 40;Repeat step 16 for
tmptable with file format CSV.SELECT COUNT (*) FROM db1.tmp;SELECT AVG(age) FROM db1.tmp where lastname = 'Davis' and age > 30 and age < 40;
Performance Result
- The following table shows the time taken (in seconds) to run each SQL query in the specific file format table without SNAPPY compression.
- By default, ZLIB compression is enabled for any managed ORC-based table in
Hiveengine in CDW unless specified.
| File Format | Engine | INSERT | SELECT COUNT (1st) | SELECT COUNT (2nd) | SELECT AVG(1st) | SELECT AVG(2nd) |
|---|---|---|---|---|---|---|
| CSV | Hive | N.A. | 26.83 | 2.28 | 44.2 | 4.1 |
| ORC (ZLIB) | Hive | 507 | 0.40 | 0.39 | 8.13 | 0.39 |
| Avro | Hive | 355 | 0.40 | 0.38 | 207 | 0.40 |
| Parquet | Hive | 332 | 0.38 | 0.38 | 11.78 | 0.37 |
| Parquet | Impala | 32 | 0.36 | 0.35 | 1.76 | 1.62 |
| CSV | Impala | N.A. | 3.12 | 1.75 | 4.69 | 4.1 |
Conclusion
- In comparison to running the same SQL queries in other solution, CDW in CDP Private Cloud platform might take shorter duration to process the queries - thanks to its high-speed caching mechanism especially when running the same query repeatedly.
- Parquet stands out in terms of running the interactive SQL query at the fastest speed. As it is a pioneer file format for Impala, running SQL query in Parquet-based table in Impala produces quicker result compared to running the same query in Hive engine. Impala is endorsing Parquet while it has some limitations supporting other file formats.
- Although Parquet emerges as the winner in terms of performance, Avro and ORC are still very relevant for other use cases and objectives. Avro is popular for its schema evolution mechanism. ORC provides high efficiency in terms of storing the Hive data and is usually positioned for ETL/ELT process.