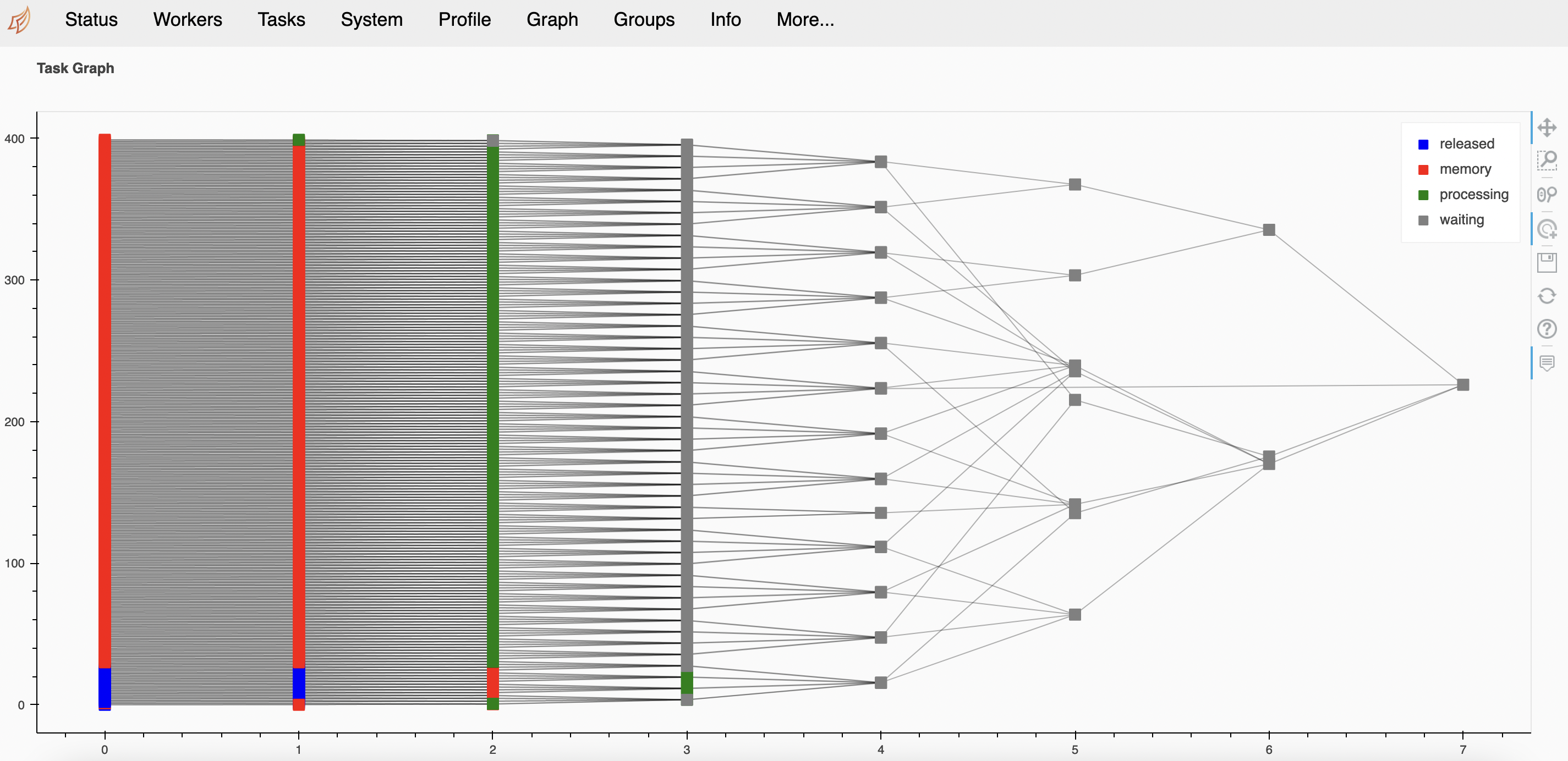
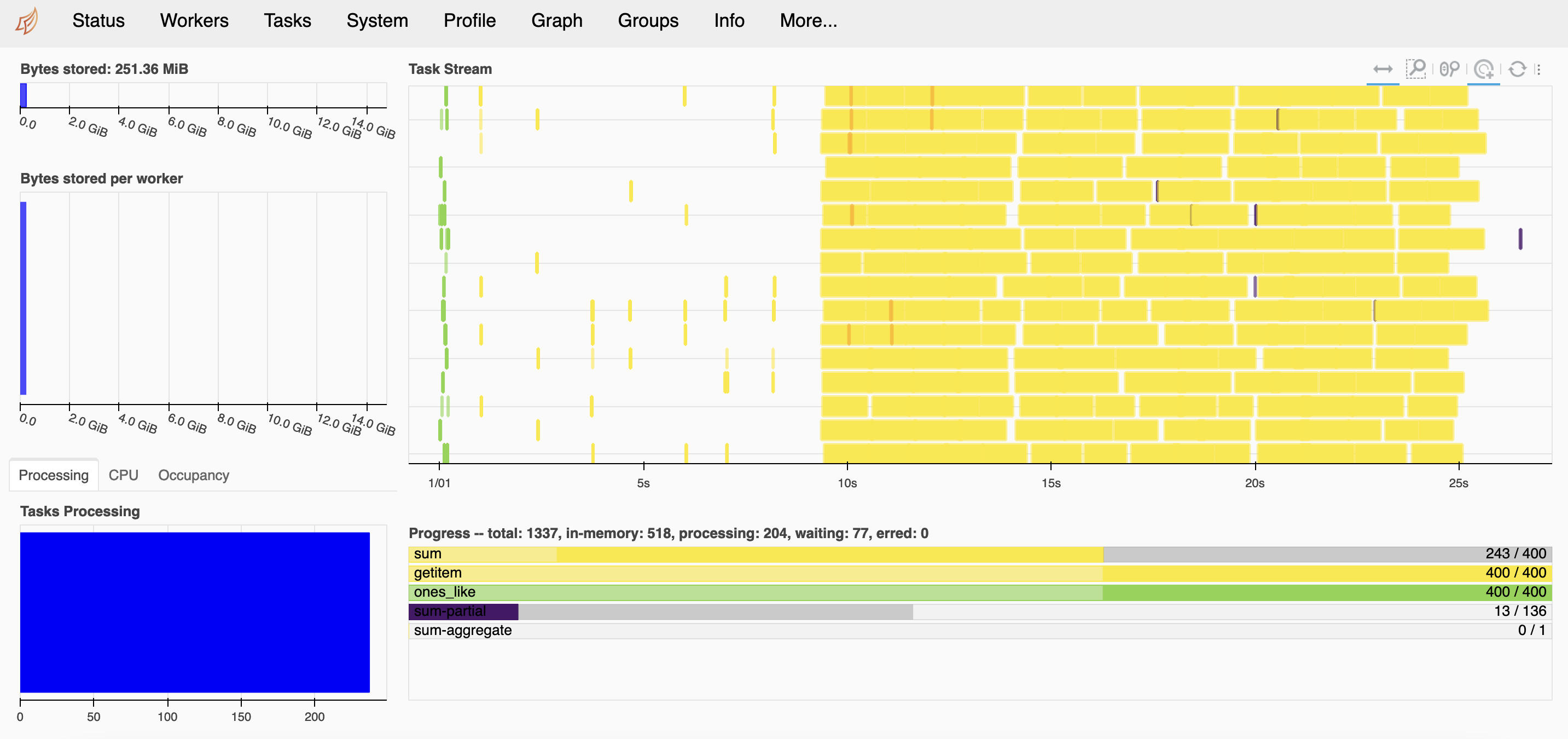
Dask is created to enhance Python performance by using distributed computing. To do so, Dask offers a list of libraries that mimics the popular data science tools such as numpy and pandas. For instance, Dask arrays organize Numpy arrays, break them into chunks to complete the computation process in a parallel fashion. As a result, large dataset can be processed using multiple nodes as opposed to the typical single node resource. This article describes the behavioural outcome in terms of speed and CPU utilization when using Dask arrays with different chunk sizes.
The following experiments are carried out using Jupyterlab notebook in Cloudera Machine Learning (CML) on the Kubernetes platform powered by Openshift 4.8 with the hardware specification as described below. Here’s the link to download the complete notebook.
[########################################] | 100% Completed | 42.8s
Total size: 40000000000.0
Restart the kernel. Create the same array shape with smaller number of chunks.
# Restart kernel
# Take shorter duration to complete with smaller number (400) of chunks.
importdask.arrayasdaarrayshape=(200000,200000)chunksize=(10000,10000)x=da.ones(arrayshape,chunks=chunksize)x
Array
Chunk
Bytes
298.02 GiB
762.94 MiB
Shape
(200000, 200000)
(10000, 10000)
Count
400 Tasks
400 Chunks
Type
float64
numpy.ndarray
Add the values of the array and take note of the completion time.
[########################################] | 100% Completed | 26.9s
Total size: 40000000000.0
By default, Dask does automatic chunking. Find out the chunk size created by the system.
# Restart kernel
# Allow automatic assignment of chunks. The system assigns 2500 tasks in this example.
importdask.arrayasdaarrayshape=(200000,200000)x=da.ones(arrayshape)x
Array
Chunk
Bytes
298.02 GiB
122.07 MiB
Shape
(200000, 200000)
(4000, 4000)
Count
2500 Tasks
2500 Chunks
Type
float64
numpy.ndarray
Add the values of the array based on the chunk size created by Dask. Take note of the completion time.
[########################################] | 100% Completed | 35.8s
Total size: 40000000000.0
Restart the kernel. Create a distributed Dask with task scheduler pod.
importosimporttimeimportcdswimportdaskdask_scheduler=cdsw.launch_workers(n=1,cpu=2,memory=2,code=f"!dask-scheduler --host 0.0.0.0 --dashboard-address 127.0.0.1:8090",)# Wait for the scheduler to start.
time.sleep(10)
Obtain the Dask URL and access the DASK UI portal.
Total size: 40000000000.0
CPU times: user 3min 2s, sys: 2min 47s, total: 5min 50s
Wall time: 26.9 s
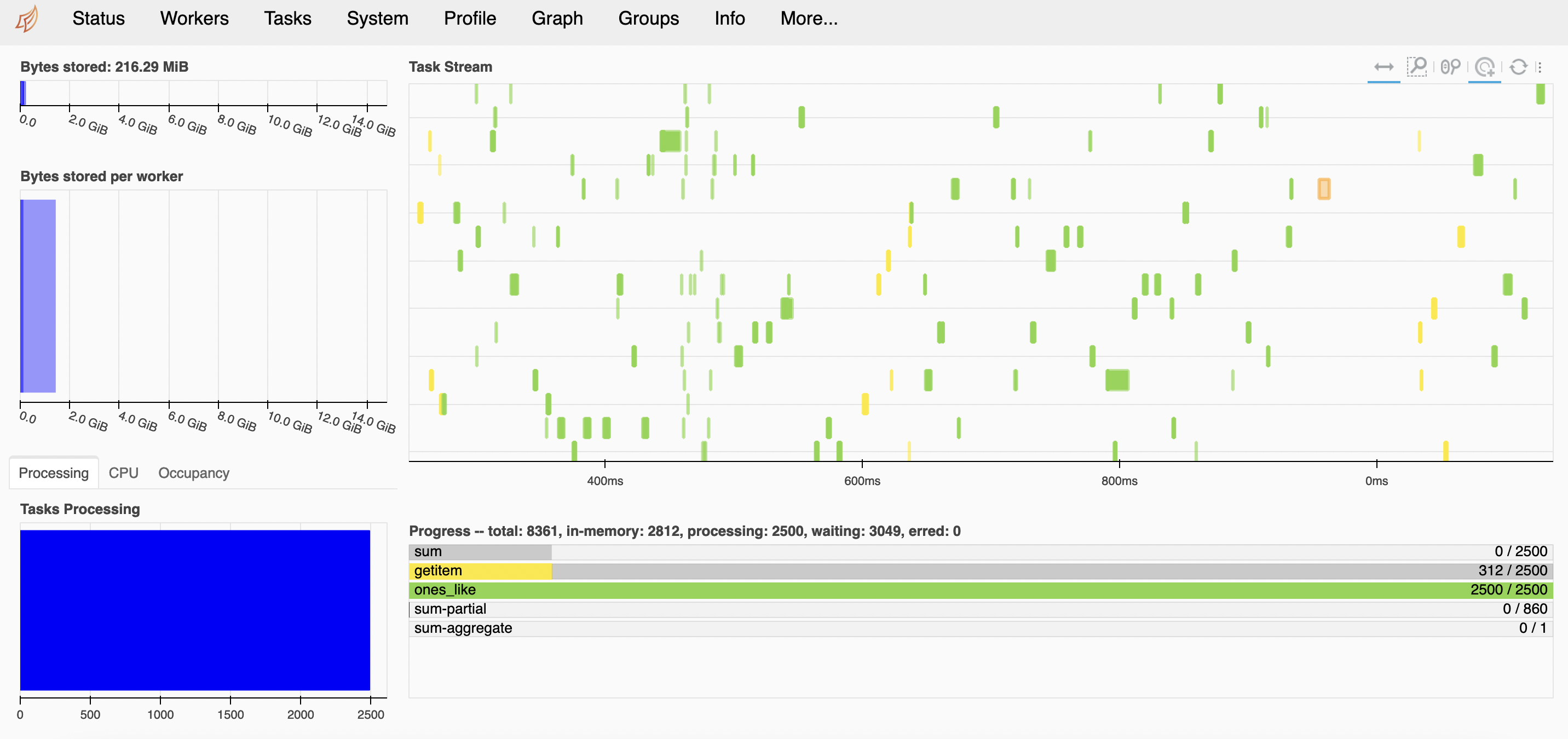
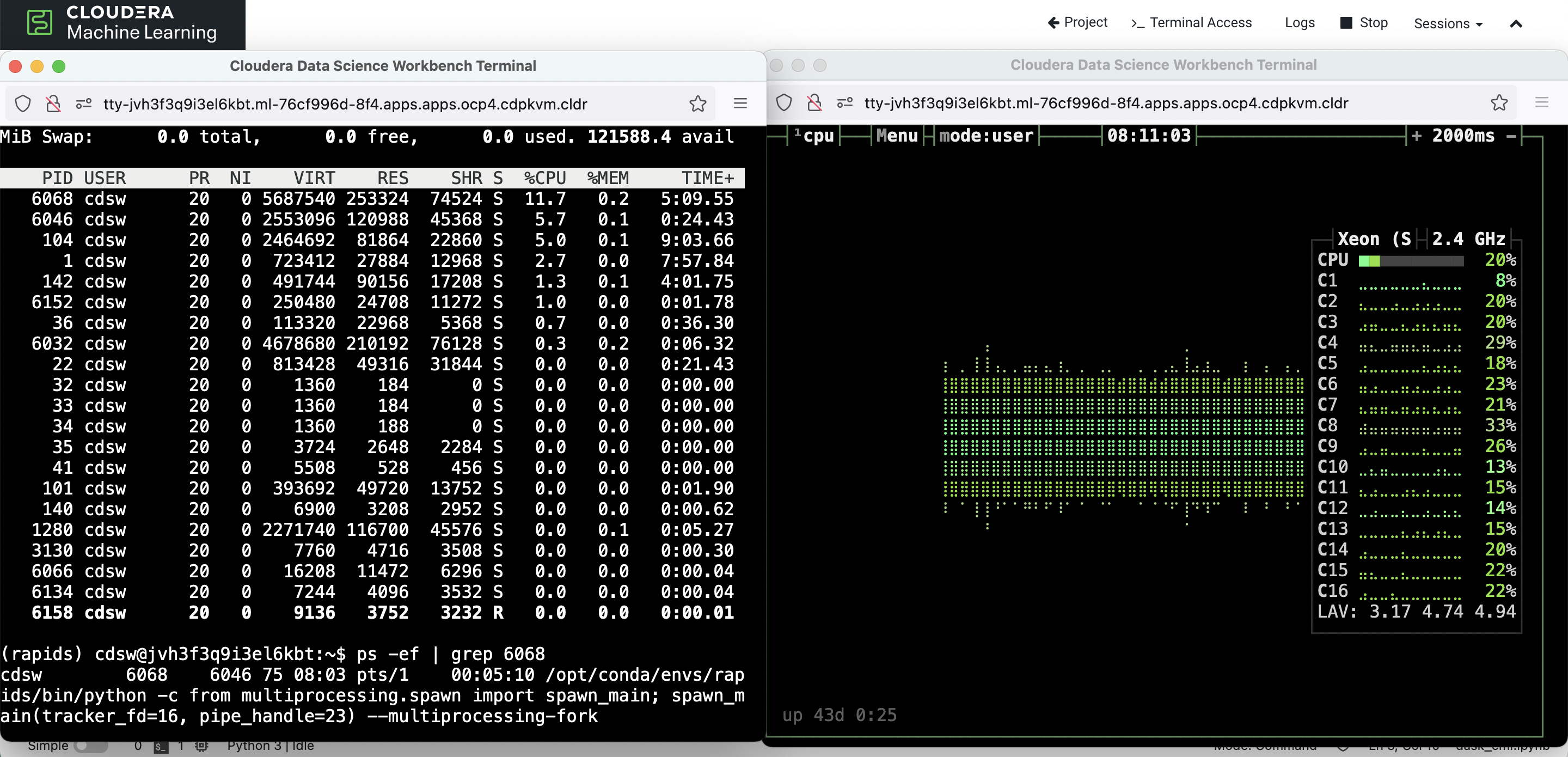
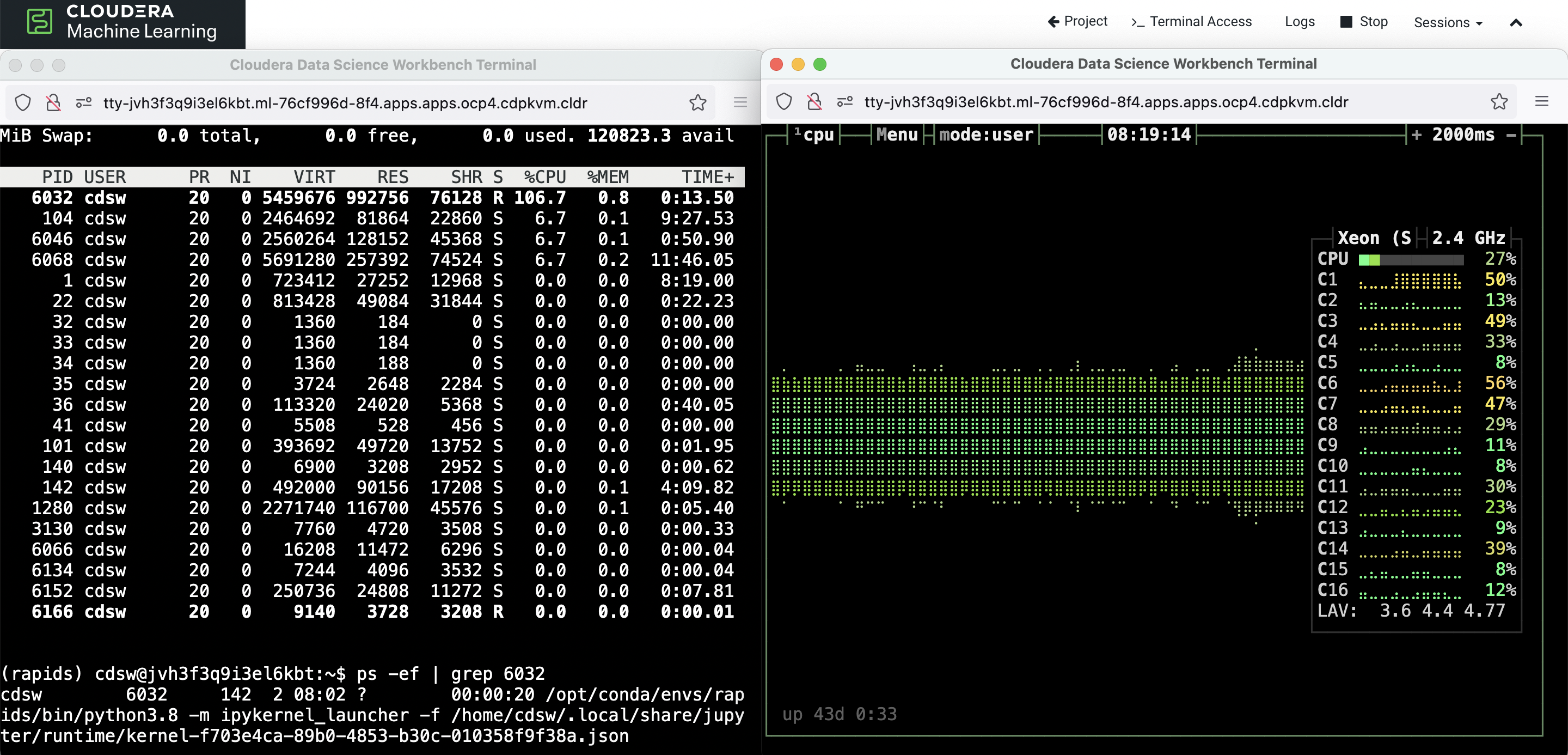
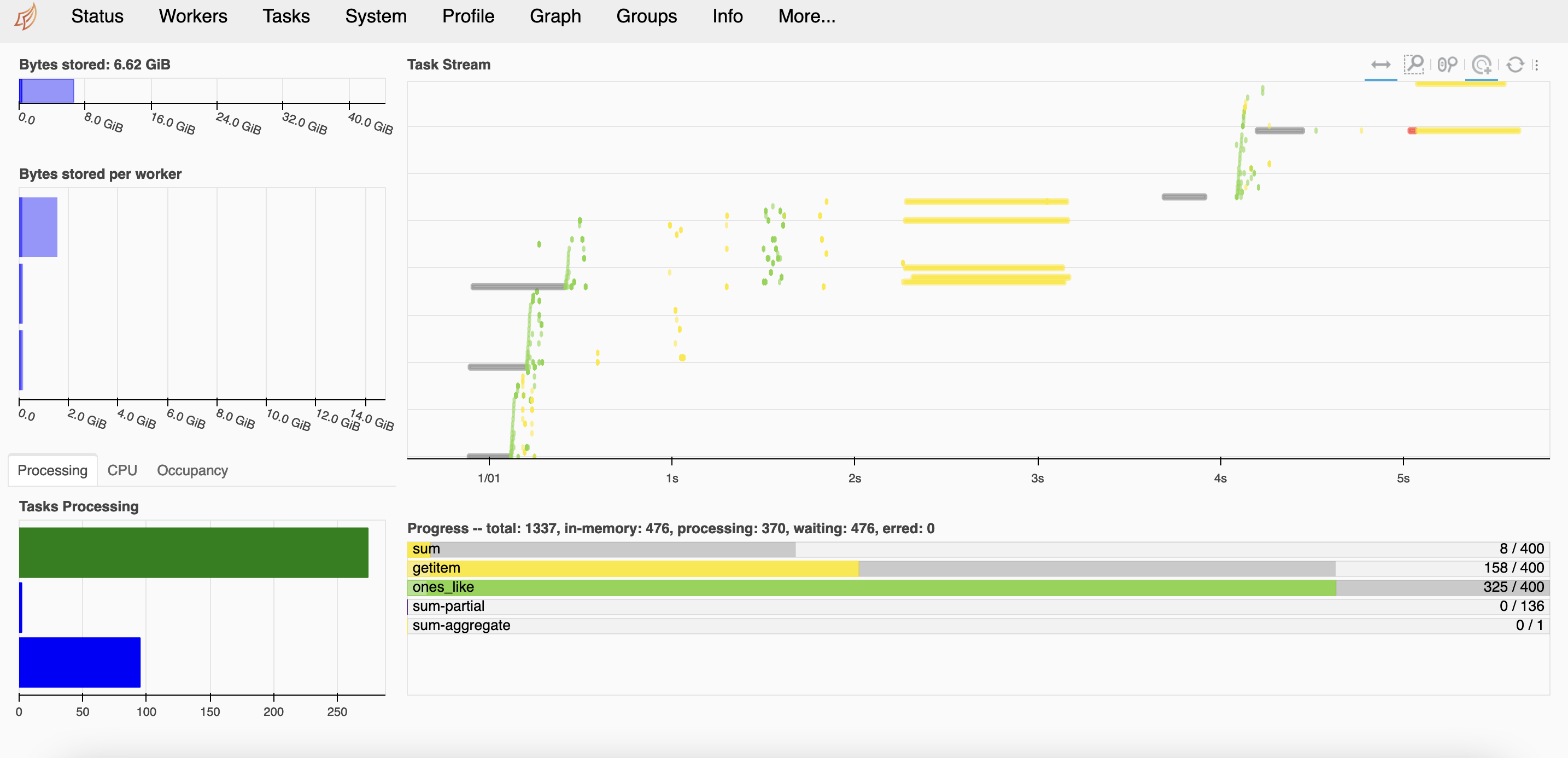
The CPU utilization graph shows that ‘threads’ scheduler uses all the available CPU cores in the hosting node to complete the tasks. It doesn’t use Dask-worker.
Dask with Multiple Worker Pods
Restart the kernel and create a new Dask cluster.
importosimporttimeimportcdswimportdaskdask_scheduler=cdsw.launch_workers(n=1,cpu=2,memory=2,code=f"!dask-scheduler --host 0.0.0.0 --dashboard-address 127.0.0.1:8090",)# Wait for the scheduler to start.
time.sleep(10)
# Obtain the Dask UI address.
print("//".join(dask_scheduler[0]["app_url"].split("//")))
Create 3 new CML worker pods attach them to the Dask cluster.
# Assign 3 worker nodes to the Dask cluster.
more_worker=3dask_workers=cdsw.launch_workers(n=more_worker,cpu=2,memory=32,code=f"!dask-worker {scheduler_url}",)# Wait for the workers to start.
time.sleep(10)
Total size: 40000000000.0
CPU times: user 329 ms, sys: 113 ms, total: 443 ms
Wall time: 22.9 s
Dask with NVIDIA GPU
Restart the kernel. Use GPU to compute the same array shape by using cuda library on the pod attached with NVIDIA GPU card. Take note of the completion time.
CPU times: user 1.09 s, sys: 2.34 s, total: 3.43 s
Wall time: 2.5 s
Total size: 40000000000.0
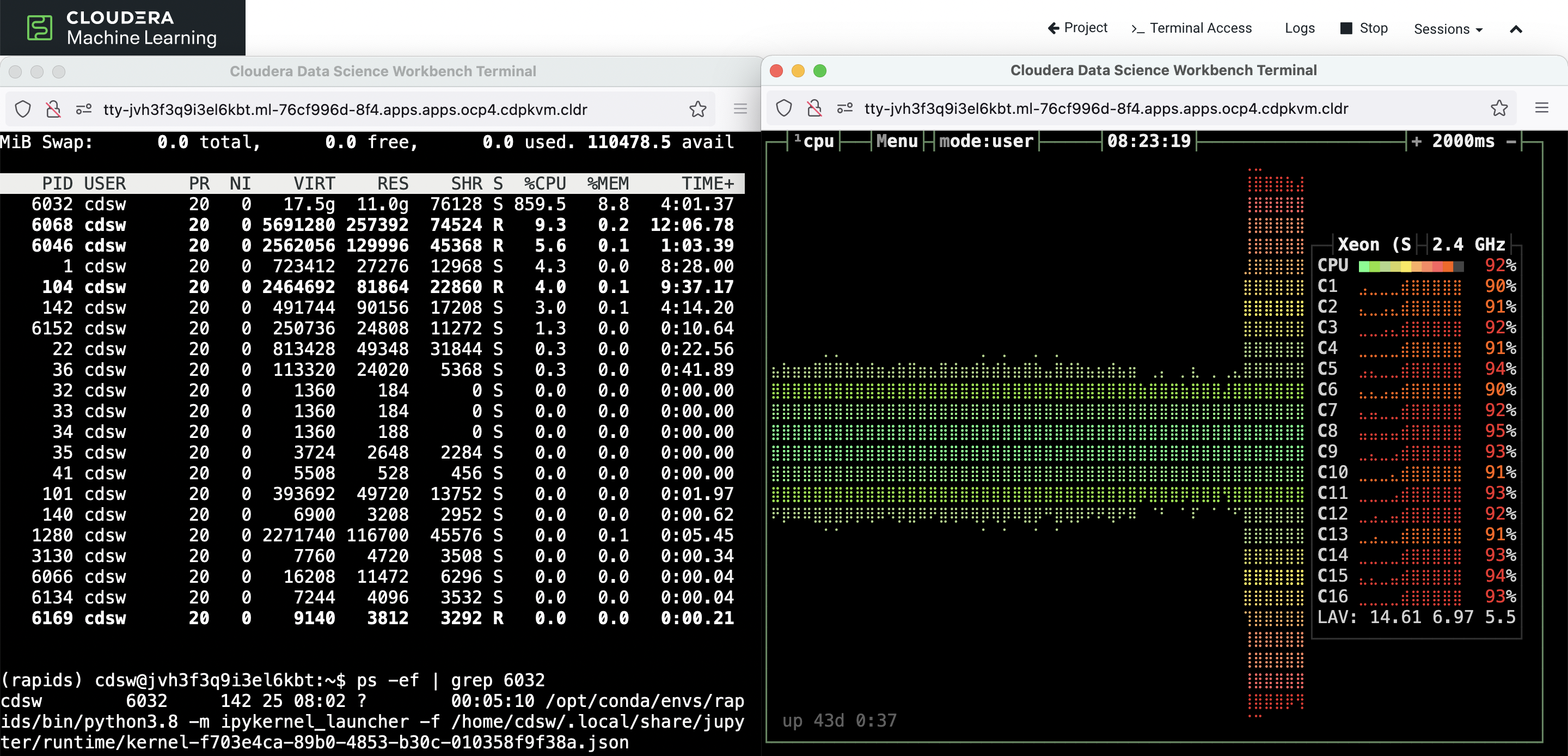
The following graph displays the GPU utilization during the execution of the above tasks.
Conclusion:
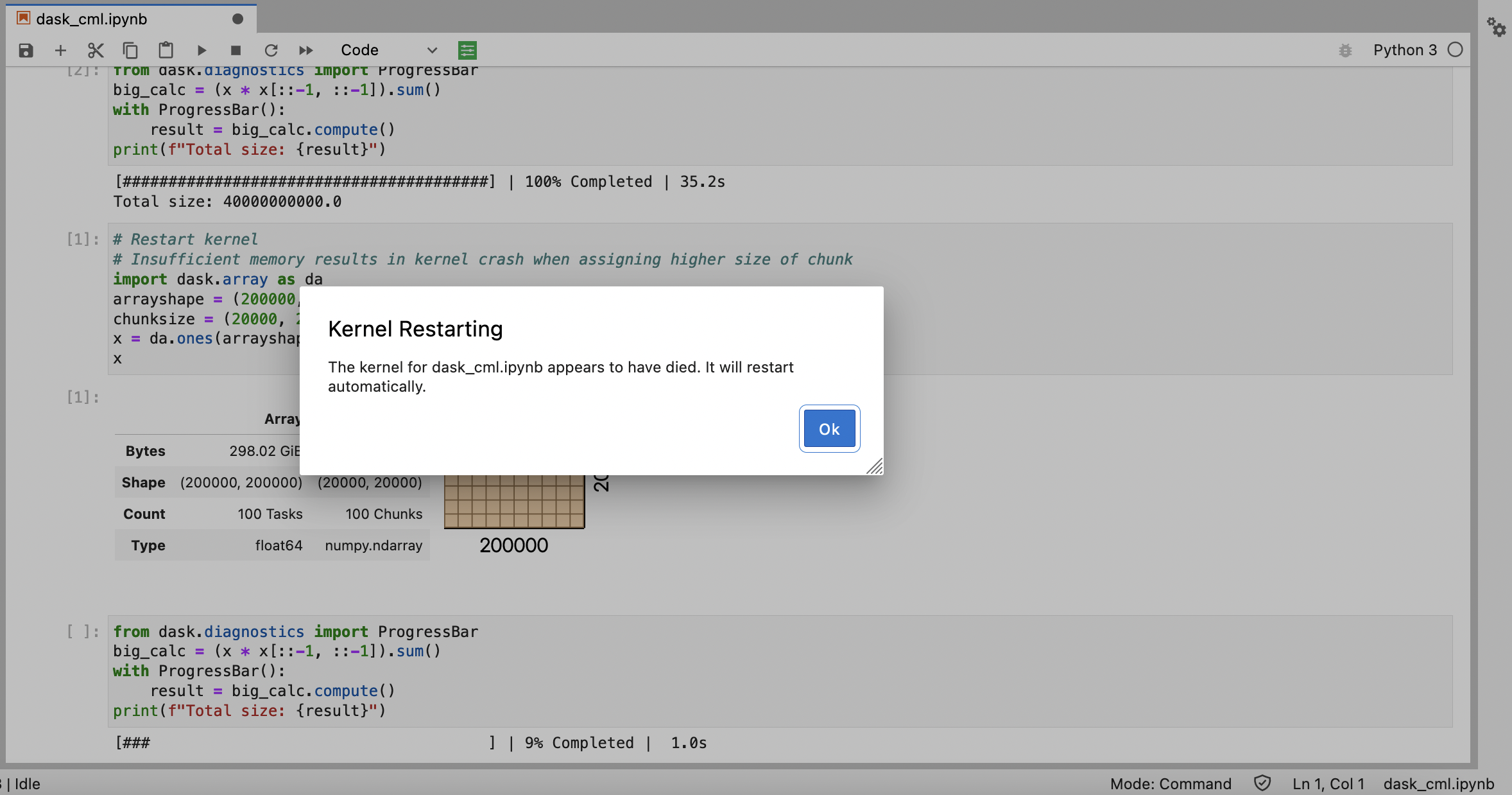
The performance output of Dask depends heavily on the chunk size assignment. Higher chunk size results in smaller number of tasks and allows execution to complete quicker. This also means higher CPU utilization when running the tasks. In addition, higher chunk size requires more memory as well. The kernel crashes due to insufficient memory when running the tasks with higher chunk size.
Using more Dask worker nodes might not necessarily result in shorter completion time as overhead applies. Dask makes sense for huge and complext dataset processing but definitely not applicable for small and simple machine learning task.
Using GPU in Dask completes the tasks much faster than using CPU for typical CPU-bound computation.